Lei Feng network: According to the author of this article Wei Xiu Sen, Xie Chenwei Department of Computer Science and Technology, Nanjing University (LAMDA), research direction for computer vision and machine learning.
Speaking of Tesla, everyone may immediately think of a fatal car accident that occurred on the Tesla Model S autopilot in May this year. Initial investigations revealed that the driver and the automatic driving system failed to notice the white body of the towing trailer under strong sunshine conditions, and therefore the brake system could not be started in time. Because the tow-type trailer is traversing the road and the vehicle body is high, this special situation causes the Model S to pass from the bottom of the trailer and the front windshield collides with the bottom of the trailer, causing the driver to die.
Coincidentally, on August 8, a man from Missouri, USA, and Joshua Neally, owner of the Tesla Model X, suddenly developed a pulmonary embolism on the way to work. With the help of the Autopilot Autopilot function of Model X, he safely arrived at the hospital. This "really depressed one" is really memorable. It is somewhat "meaning that if you lose, you will be lost and you will be lost."

Curious readers must have doubts: What exactly is the principle behind this “one by one defeat?†Which part of the autopilot system has caused a car accident due to a mistake? Which part of the technology supports the autopilot process?
Today, we talk about an important core technology autopilot systems - Image segmentation semantic (semantic image segmentation). Semantic segmentation of images is an important part of image understanding in computer vision. Not only is the demand in the industry increasingly prominent, but semantic segmentation is also one of the research hotspots in the academic world.
What is image semantic segmentation?Semantic image segmentation can be said to be the cornerstone of image understanding. It plays an important role in autopilot systems (specifically street view recognition and understanding), drone applications (landing point judgment), and wearable device applications.
We all know that an image consists of many pixels. Semantic segmentation, as the name suggests, involves grouping/segmenting pixels according to the semantic meaning of the images. The following figure is taken from PASCAL VOC, one of the standard datasets in the field of image segmentation. Among them, the left image is the original image, and the right image is the ground truth of the segmentation task: the red region represents the image pixel region whose semantics is "person", the blue and green represents the "motorbike" semantic region, and the black represents the "background", white (Edge) indicates an unmarked area.
Obviously, in the image semantic segmentation task, the input is an H×W×3 three-channel color image, and the output is a corresponding H×W matrix. Each element of the matrix indicates the corresponding position pixel in the original image. The semantic label of the representation. Therefore, the image semantic segmentation also known as "semantic annotation image" (image semantic labeling), "pixel semantic annotation" (semantic pixel labeling) or "pixels semantic grouping" (semantic pixel grouping).
194201fc2cb690431.jpg" />
From the above diagram and the question diagram, it is obvious that the difficulty in the task of image semantic segmentation lies in the word “semanticsâ€. In a real image, the same object that expresses a certain semantics is often composed of different components (eg, building, motorbike, person, etc.). At the same time, these parts often have different colors, textures, or even brightness (eg, building), which gives image semantics. Precise segmentation brings difficulties and challenges.
Semantic segmentation in the former DL eraFrom the most simple pixel level "Threshold" (thresholding methods), segmentation pixel clustering (clustering-based segmentation methods) based on the segmentation method "graph partitioning" of (graph partitioning segmentation methods), in deep learning (deep learning DL) Before "unified rivers and lakes", the work on the semantic segmentation of images can be described as "a hundred flowers bloom together." Here, we only use the classic segmentation method based on graph divisions of “normalized cut†[1] and “grab cut†[2] as an example to introduce the research on semantic segmentation in the former DL era.
The Normalized cut (N-cut) method is one of the most well-known methods for semantic segmentation based on graph partitioning. In 2000, Jianbo Shi and Jitendra Malik published the top journal TPAMI in related fields. In general, the traditional semantic segmentation method based on graph division is to abstract the image into the form of graph G = (V, E) (V is the graph node, E is the graph's edge), and then graph theory is used. The theory and algorithm in the semantic segmentation of the image.
Cut algorithm commonly used method (min-cut algorithm) for the classical minimum. However, in the calculation of edge weights, the classical min-cut algorithm only considers local information. As shown in the following figure, taking a bipartite graph as an example (to divide G into disjoint parts, two parts), if only the local information is considered, then separating a point is obviously a min-cut, so the result of the graph division is similar or In this way, outliers, and from the overall point of view, the two groups are actually divided into two groups.
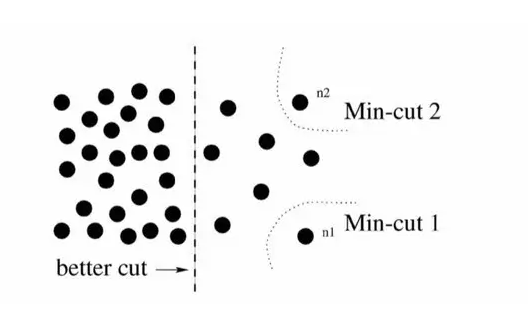
In response to this situation, N-cut proposes a method of considering global information for graph partitioning, that is, connecting weights between two partitioned parts A, B and full graph nodes (assoc(A, V) and assoc(B,V)) take into account:
As a result, in the outlier division, one of the items in the group will be close to one, and such a division of the graph obviously cannot be made a smaller value. Therefore, the purpose of considering the global information and discarding the separated group points is achieved. This operation is similar to the normalization operation of features in machine learning, so it is called normalized cut. N-cut can not only deal with the second type of semantic segmentation, but also extend the bipartite graph into a K-way (-way) graph segmentation to complete multi-semantic image semantic segmentation, as shown in the following illustration.

Grab cut is a famous interactive image semantic segmentation method proposed by Microsoft Cambridge Research Institute in 2004. Like N-cut, the grab cut is also based on graphs, but the grab cut is an improved version of it and can be thought of as an iterative semantic segmentation algorithm. Grab cut uses the texture (color) information and border (contrast) information in the image, so that only a small amount of user interaction can get a good background split result.
In the grab cut, the foreground and background of the RGB image are modeled using a gaussian mixture model (GMM). Two GMMs are used to describe the probability that a pixel belongs to the foreground or the background. The number of Gaussian components in each GMM is generally set to be.
Next, we use the Gibbs energy function to globally characterize the entire image, and then iteratively obtain the parameters that make the energy equation reach the optimal value as the optimal parameters of the two GMMs. After the GMM is determined, the probability that a pixel belongs to the foreground or background is determined.
In the process of interaction with the user, grab cut interactively provides two ways: One to surround block (bounding box) of the auxiliary information; graffiti to another line (scribbled line) as auxiliary information. The following figure shows an example. The user provides a bounding box at the beginning. Grab cut defaults that the pixel in the box contains the main object/foreground. After that, it is divided and solved by the iterative graph, and you can return the foreground result of the deduction. You can find even the With a slightly more complex image, the grab cut still has a good performance.

However, the cut effect of the grab cut is unsatisfactory when dealing with the figure below. At this time, additional human information is needed to provide stronger auxiliary information: the background area is marked with red lines/points, and the foreground area is marked with white lines. Based on this, running the grab cut algorithm again to obtain the optimal solution can get more satisfactory semantic segmentation results. Although the effect of the grab cut is excellent, the disadvantages are also very obvious. First , it can only deal with the semantic segregation problem of the second type. Second, it requires human intervention and cannot be completely automated.

Semantic segmentation in the DL era
In fact, it is not difficult to see that the semantic segmentation of the former DL era is based on the low-level visual cues of image pixels. Since such a method does not have an algorithm training phase, the computational complexity is often not high, but the segmentation effect is not satisfactory on difficult segmentation tasks (if no artificial auxiliary information is provided).
After computer vision entered the era of deep learning, semantic segmentation also entered a completely new stage of development. It was represented by a series of convolutional neural networks (FCN), a series of semantic segmentation based on "training" of convolutional neural networks. The methods have been proposed in succession, and the semantic segmentation accuracy of images has been frequently refreshed. The following describes three typical methods of semantic segmentation in the DL era.
Full convolutional neural network [3]
Full convolutional neural network FCN can be said to be the pioneering work of deep learning on image semantic segmentation task. It came from Trevor Darrell group of UC Berkeley and was published in CVPR 2015, the top conference in the field of computer vision, and won the best paper honorable mention.
The idea of ​​the FCN is very intuitive, that is, it performs pixel-level end-to-end semantic segmentation directly. It can be implemented based on the mainstream deep convolutional neural network model (CNN). As the so-called "full convolutional neural network", in the FCN, the traditional full-connection layers fc6 and fc7 are realized by the convolutional layer, and the final fc8 layer is replaced by a 21-channel 1x1 convolutional layer. , as the final output of the network. The reason why there are 21 channels is because PASCAL VOC data contains 21 categories (20 object categories and one "background" category).
The following figure shows the network structure of the FCN. If the original image is H×W×3, the response tensor corresponding to the original image can be obtained after several stacks of convolution and pooled layer operations. The first layer is the ith layer. The number of channels. It can be seen that due to the downsampling effect of the pooling layer, the length and width of the response tensor are smaller than the length and width of the original image, which brings problems to direct training at the pixel level.
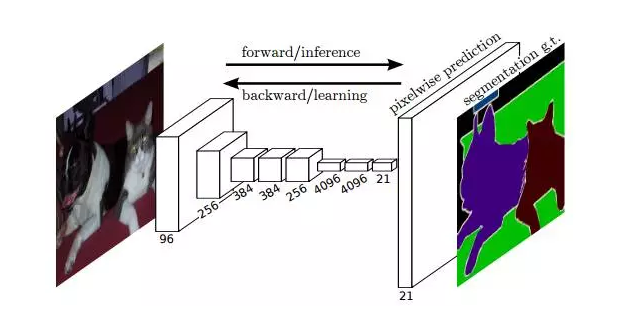
In order to solve the problem caused by downsampling, FCN uses bilinear interpolation to upsample the length and width of the response to the original image size. In addition, in order to better predict the details of the image, FCN will also respond to the shallow response in the network. Also consider coming in. Specifically, the responses of Pool4 and Pool3 are also taken as the output of the model FCN-16s and FCN-8s respectively, and combined with the output of the original FCN-32s to perform the final semantic segmentation prediction (as shown in the following figure). .

The following figure shows the result of the semantic segmentation of different layers as output. It can be clearly seen that the different degrees of semantic segmentation result from the different downsampling multiples of the pooling layer. For example, FCN-32s, because it is the last layer of FCN convolution and pooled output, the model has the highest downsampling multiple, and its corresponding semantic segmentation result is the coarsest; FCN-8s can be obtained because the downsampling multiple is small. Finer segmentation results.

Dilated Convolutions [4]
One of the disadvantages of FCN is that due to the existence of the pooling layer, the response tensor (length and width) is getting smaller and smaller , but the original design of the FCN requires the same output as the input size, so the FCN does upsampling. . However, up-sampling cannot retrieve lost information completely without loss.
Dilated convolution is a good solution for this - since pooled down-sampling operations can cause information loss, the pooling layer is removed. However, the removal of the pooling layer leads to a smaller receptive field at each level of the network, which reduces the prediction accuracy of the entire model. The main contribution of Dilated convolution is how to remove the down sampling operation of the pool without reducing the receptive field of the network.
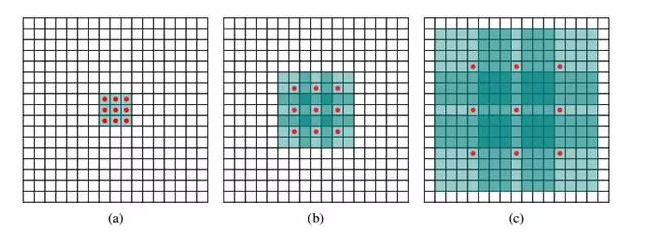
Take the 3×3 convolution kernel as an example. In the convolution operation, the traditional convolution kernel multiplies the convolution kernel with the “continuous†3×3 patch in the input tensor and then sums them (as shown in the following figure. The red dot is the input "pixel" corresponding to the convolution kernel and green is its perceived field in the original input. The convolution kernel in differentiated convolution is to convolve the input tensor 3×3 patch across certain pixels.
As shown in Figure b below, after removing one layer of pooled layer, we need to replace the traditional convolution layer with a dilated=2 dilated convolution layer after removing the pooled layer. At this time, the convolution kernel will input the tensor. Every other "pixel" position is used as the input patch for convolution calculation. It can be seen that the perceived field corresponding to the original input has been expanded (dilate). Similarly, if a pooled layer is removed, it will be after The convolutional layer is replaced by the dilated=4 dilated convolution layer, as shown in Figure c. In this way, even if the pooling layer is removed, the receptive field of the network can be guaranteed, thereby ensuring the accuracy of image semantic segmentation.
As can be seen from the following image semantic segmentation effect graphs, the use of the dilated convolution technique can significantly improve the recognition of semantic categories and the fineness of the segmentation details.

Post-processing operations represented by conditional random fields
Many current depth learning image frame work is divided by the semantic CRFs (conditional random field, CRF) to optimize the final result of the semantic prediction of the post-processing operation.
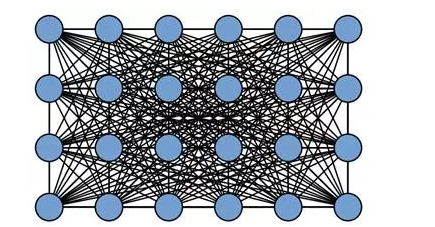
In general, CRF regards the category to which each pixel in the image belongs as a variable, and then considers the relationship between any two variables to create a complete graph (as shown in the figure below).
In the fully-linked CRF model, the corresponding energy function is:
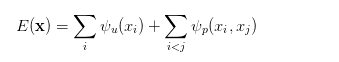
It is a unitary term that represents the semantic class corresponding to the pixel. Its category can be obtained from the prediction result of the FCN or other semantic segmentation model. The second item is the binary item, and the binary item can consider the semantic relationship/relationship between pixels. Go in. For example, pixels such as "sky" and "bird" are adjacent in the physical space, and they should be larger than the pixels in "sky" and "fish". Finally, by optimizing the CRF energy function, the FCN image semantic prediction results are optimized, and the final semantic segmentation results are obtained.
It is worth mentioning that there has been work [5] to embed the CRF process that was originally separated from the deep model training into the neural network, that is, to integrate the FCN+CRF process into an end-to-end system. The energy function of the last predicted result of the CRF can be used to directly guide the training of the FCN model parameters and obtain better image semantic segmentation results.

As the saying goes, "no free lunch". Although deep semantic learning based image segmentation techniques can achieve a segmentation effect that is more rapid than traditional methods, their requirements for data labeling are too high: not only do they require massive amounts of image data, but they also need to provide accurate pixel-level tag information ( Semantic labels) . Therefore, more and more researchers began to turn our attention to weak supervision of the semantic image segmentation under (weakly-supervised) conditions. In this kind of problem, the image only needs to provide image level annotation (eg, "person", "car", no "television") without requiring expensive pixel level information to achieve semantic separation comparable to existing methods. Accuracy.
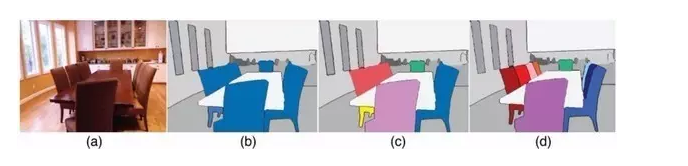
Further, examples of the level (instance level) image semantic segmentation problem is also popular. Such problems not only require image segmentation for different semantic objects, but also require segmentation of different individuals of the same semantics (for example, the pixels of the nine chairs appearing in the figure are separately labeled with different colors).
Finally, video-based foreground/object segmentation (video segmentation) is also one of the new hotspots in the field of semantic segmentation of computer vision in the future. This setting actually fits the real application environment of the autopilot system.
References:
[1] Jianbo Shi and Jitendra Malik. Normalized Cuts and Image Segmentation, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22, No. 8, 2000.
[2] Carsten Rother, Vladimir Kolmogorov and Andrew Blake. "GrabCut"--Interactive Foreground Extraction using Iterated Graph Cuts, ACM Transactions on Graphics, 2004.
[3] Jonathan Long, Evan Shelhamer and Trevor Darrell. Fully Convolutional Networks for Semantic Segmentation. IEEE Conference on Computer Vision and Pattern Recognition, 2015.
[4] Fisher Yu and Vladlen Koltun. Multi-scale Context Aggregation by Dilated Convolutions. International Conference on Representation Learning, 2016.
[5] Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang and Philip HS Torr. Conditional Random Fields as Recurrent Neural Networks. International Conference on Computer Vision, 2015.
Lei Feng network (search "Lei Feng network" public concern) Note: The author of this article starting machine heart, authorized Lei Feng network release. If you need to reprint please contact the original author, and indicate the source can not be deleted.
Features
â—† Wide Application
Widely used for various kinds of electrical products, instrument, car, boat, household appliances such as lights, water dispenser, treadmill, coffee pot, speaker, electric car, motorcycle, TV, massage machine etc.
â—† Easy to install and use
3 PIN on-off rocker switch with SPST design, simple installation, freely turn on or off the load which you want to control.
â—† High Operating Life
Made of high quality polyamide eP(Nylon PA66) material, this sturdy mini boat rocker switch is born for anti-corrosion,anti-acid and high resistant with silver terminals.100,000 times of ON/OFF operating life span.
Rocker Switch,Waterproof Rocker Switch,Custom Rocker Switches,Mini Rocker Switch
Ningbo Jialin Electronics Co.,Ltd , https://www.donghai-switch.com