To do some calculation acceleration work, we must first think about several issues: What application should be accelerated, what is the bottleneck of the application, and then refer to the predecessor's work to select the appropriate solution for this bottleneck. Premature attachment to the technical details of fpga is easy for many details of the nurse. Now software define network/flash/xxx, it is already the trend.
WHEN? Deep learning heterogeneous computing statusWith the rapid growth of Internet users and the rapid expansion of data volume, the demand for computing in data centers is also rising rapidly. At the same time, the rise of computationally intensive areas such as artificial intelligence, high-performance data analysis, and financial analysis has far exceeded the power of traditional CPU processors.
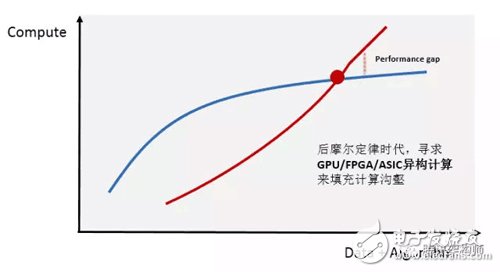
Heterogeneous computing is considered to be the key technology to solve this computing gap at present. Currently, "CPU+GPU" and "CPU+FPGA" are the most heterogeneous computing platforms that the industry pays attention to. They have the computational performance advantages of higher efficiency and lower latency than traditional CPU parallel computing. Faced with such a huge market, a large number of enterprises in the technology industry have invested a large amount of capital and manpower, and the development standards for heterogeneous programming are gradually maturing, while mainstream cloud service providers are actively deploying.

The industry can see that giant companies such as Microsoft have deployed high-volume FPGAs for AI inference acceleration. What are the advantages of FPGAs over other devices?
Flexibility: Programmability Natural Adaptation ML Algorithm in Rapid Evolution
DNN, CNN, LSTM, MLP, reinforcement learning, decision trees, etc.
Arbitrary precision dynamic support
Model compression, sparse network, faster and better network
Performance: Building real-time AI service capabilities
Low latency prediction capability compared to GPU/CPU orders of magnitude
Single watt performance capability compared to GPU/CPU orders of magnitude
Scale
High-speed interconnect IO between boards
Intel CPU-FPGA architecture
At the same time, the short board of FPGA is also very obvious. FPGA uses HDL hardware description language for development, with long development cycle and high entry threshold. Taking separate classic models such as Alexnet and Googlenet as an example, custom-developed accelerated development of a model often takes several months. The business side and the FPGA acceleration team need to balance the algorithm iteration and adapt the FPGA hardware acceleration, which is very painful.
On the one hand, FPGAs need to provide low-latency high-performance services that are competitive with CPU/GPU. On the one hand, FPGA development cycle is required to keep up with the iterative cycle of deep learning algorithms. Based on these two points, we design and develop a universal CNN accelerator. Taking into account the general design of the mainstream model operator, the model acceleration is driven by the compiler to generate instructions, which can support model switching in a short time. At the same time, for the emerging deep learning algorithm, the correlation operator is fast on this common basic version. Development iterations, model acceleration development time has been reduced from the previous months to now one to two weeks.
HOW? Generic CNN FPGA ArchitectureThe overall framework of the general CNN accelerator based on FPGA is as follows. The CNN model trained by Caffe/Tensorflow/Mxnet framework generates the corresponding instructions of the model through a series of optimizations of the compiler. At the same time, the image data and model weight data are pre-processed according to the optimization rules. After processing and compression, it is sent to the FPGA accelerator through PCIe. The FPGA accelerator works in full accordance with the instruction set in the instruction buffer. The accelerator executes the instruction in the complete instruction buffer to complete the calculation acceleration of a picture depth model. Each functional module is relatively independent and is only responsible for each individual module calculation request. The accelerator is separated from the deep learning model, and the data dependencies and pre- and post-execution relationships of each layer are controlled in the instruction set.
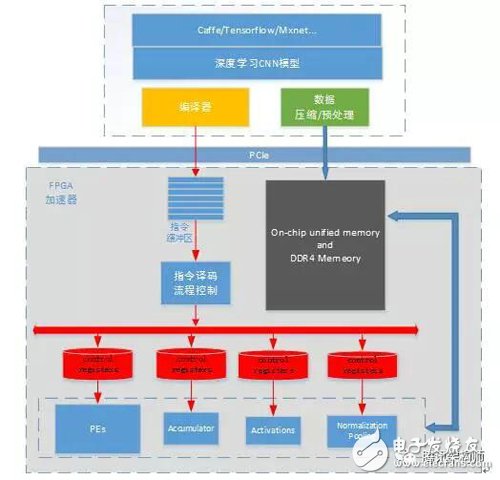
In simple terms, the main job of the compiler is to analyze and optimize the model structure, and then generate an instruction set that the FPGA executes efficiently. The guiding idea of ​​compiler optimization is: higher MAC dsp computational efficiency and less memory access requirements.
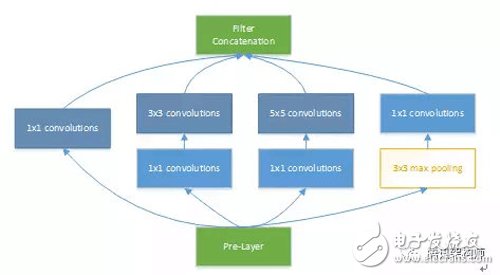
Next, we take the Googlenet V1 model as an example to do a simple analysis of the accelerator design optimization ideas. The IncepTIon v1 network, which combines 1x1, 3x3, 5x5 conv and 3x3 pooling stacks, increases the bandwidth of the network and increases the network's adaptability to scale. The figure below shows the basic structure of IncepTIon in the model.
Data dependency analysis
This section mainly analyzes the flowable and parallelizable calculations in the mining model. Streamlined design can increase the utilization of computing units in the accelerator, and parallelized calculations can utilize as many computational units as possible at the same time.
Regarding the pipeline, the analysis part includes the flow of data from the DDR loading to the SRAM on the FPGA and the calculation of the PE. The optimization of the memory access time overlap; the DSP calculates the calculation control process of the entire column to ensure the improvement of the DSP utilization.
With regard to parallelism, it is necessary to focus on the parallel relationship between PE computing arrays and "post-processing" modules such as activation, pooling, and normalization. How to determine data dependencies and prevent conflicts is the key to design here. In IncepTIon, it can be seen from its network structure that the 1x1 convolution calculation of branch a/b/c and the pooling in branch d can be calculated in parallel, and there is no data dependency between the two. By optimizing here, the calculation of the 3x3 max pooling layer can be completely overlapped.
Model optimization
There are two main considerations in the design: finding model structure optimization and fixed-point support for dynamic precision adjustment.
FPGAs are devices that support a large number of computational parallels. Finding higher dimensional parallelism from the model structure makes sense for computational efficiency and memory access reduction. In IncepTIon V1, we can see the first layer 1x1 convolution layer of branch a\ branch b\ branch c, the input data is exactly the same, and the stride and pad of the convolution layer are the same. So can we align on the output feature map dimension for overlay? After the overlay, the memory demand for input data is reduced to 1/3.
On the other hand, in order to give full play to the characteristics of FPGA hardware acceleration, the model's Inference process requires a fixed-point operation of the model. In fpga, the performance of int8 can be doubled that of int16, but in order to enable customers in the company and Tencent Cloud to deploy their training floating point model without perception, without retrain int8 model to control the loss of precision, we A fixed-point int16 scheme that supports dynamic precision adjustment is used. In this way, user-trained models can be deployed directly through the compiler with virtually no loss of precision.
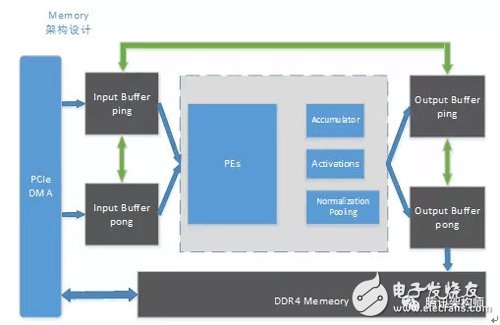
Memory architecture design
The bandwidth problem is always one of the bottlenecks in the computer architecture to limit performance, while memory access directly affects the power consumption efficiency of the acceleration device.
In order to minimize the DDR memory access during model calculation, we designed the following memory architecture:
Input buff and output buffer ping-pong design to maximize pipeline and parallelism
Support for inner-copy operations between Input buff and output buffer itself
Cross-copy operation between Input buff and output buffer
With this architecture, for most current mainstream models, the accelerator can hold all the intermediate data on the FPGA chip, and there is no need to consume any additional memory operations in addition to the loading of the model weights. For models that cannot store the middle layer feature map completely on the slice, we introduce the concept of slice fragmentation in the Channel dimension and introduce the concept of part fragmentation in the feature map dimension. Through the compiler, a convolution or pooling\Norm operation is reasonably split, and the DDR memory access operation and the FPGA acceleration calculation are streamed, and the DDR memory access requirement is minimized under the premise of ensuring the DSP calculation efficiency. .
Computing unit design
The core of the FPGA-based universal CNN accelerator is its computational unit. The current version of this accelerator is based on the Xilinx Ku115 chip design. The PE calculation unit consists of 4096 MAC dsp cores operating at 500MHz with a theoretical peak computing power of 4Tflops. The basic organizational framework is shown below.
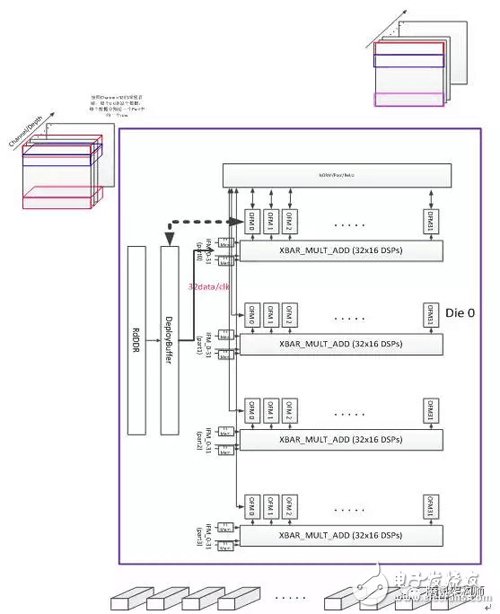
The KU115 chip is stacked by two DIE pairs, and the accelerator is placed in parallel with two processing units PE. Each PE is composed of 4 sets of 32x16=512 MAC computing DSP cores. The key to the design is to improve the data reuse in the design to reduce the bandwidth, to achieve the reuse of model weights and the reuse of each layer feature map, and improve the computational efficiency. .
Application scenario and performance comparison
Currently, the deep learning mainstream uses the GPU to do the training process in deep learning, while the online Inference deployment needs to comprehensively consider the real-time, low-cost and low-power features to select the acceleration platform. According to the depth learning floor scene classification, advertising recommendation, voice recognition, real-time monitoring of picture/video content, etc. are real-time AI services and smart traffic, smart speakers and unmanned terminals such as real-time low-power scenarios, FPGA can be compared with GPU Provide strong real-time, high-performance support for the business.
What is the platform performance, development cycle and ease of use for the user?
Acceleration performance
Take the actual googlenet v1 model as an example, the CPU test environment: 2 6-core CPUs (E5-2620v3), 64G memory.
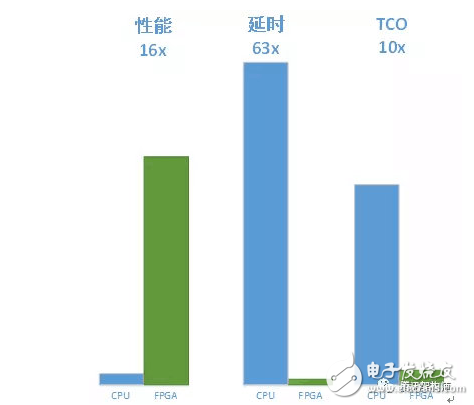
When the CPU of the whole machine is full, the single KU115-based accelerator is 16 times better than the CPU performance, the single picture detection delay is reduced from 250ms to 4ms, and the TCO cost is reduced by 90%.
At the same time, FPGA predictive performance is slightly stronger than Nvidia's GPU P4, but there is an order of magnitude optimization on latency.
Development cycle
The versatile CNN FPGA acceleration architecture supports deep learning models in the fast iterative evolution of the business, including classic models such as Googlenet/VGG/Resnet/ShuffleNet/MobileNet and new model variants.
For the classic model and the algorithm variant based on the standard layer self-study, the existing acceleration architecture can already be supported, and the corresponding instruction set of the model can be implemented by the compiler in one day to realize the deployment online.
For the special models of self-research, such as asymmetric convolution operator and asymmetric pooling operation, it is necessary to perform related operator iterative development on the platform according to the actual model structure, and the development cycle can be shortened within one to two weeks. .
Ease of use
The FPGA CNN Accelerator encapsulates the underlying acceleration process and provides an easy-to-use SDK for the service side of the acceleration platform. The business side can call the simple API function to complete the accelerated operation, and there is almost no change to the business logic itself.
If the online model needs to be changed, simply call the model initialization function and initialize the corresponding model instruction set to the FPGA. The accelerated service can be switched in a few seconds.
ConclusionThe FPGA-based universal CNN acceleration design can greatly shorten the FPGA development cycle and support the fast iteration of the business deep learning algorithm; it provides comparable computing performance to the GPU, but has the advantage of delay compared to the GPU. The versatile RNN/DNN platform is under intense development, and the FPGA Accelerator builds the most robust real-time AI service capabilities for the business.
In the cloud, at the beginning of 2017, we launched the first FPGA public cloud server in Tencent Cloud, and we will gradually introduce the basic AI acceleration capability to the public cloud.
The battlefield of AI heterogeneous acceleration is very exciting. Providing the best solution for the company and the cloud business is the direction of the continuous efforts of the FPGA team.
Micro camera is the product of modern high-tech, also known as micro monitor, which has the characteristics of small size, powerful function and good concealment.
Micro cameras are widely used, suitable for aviation, commerce, media, enterprises and institutions, families and other industries. The emergence of miniature cameras brings convenience to people's lives, and at the same time, some phenomena related to corporate secrets and personal privacy also arise.
Bottle Camera,Spy Hidden Camera,Micro camera
Jingjiang Gisen Technology Co.,Ltd , https://www.gisengroup.com