Recently, ARM has further disclosed some of the information of ML Procesor. EETimes's article “Arm Gives Glimpse of AI Coreâ€[1] and AnandTech's article “ARM Details “Project Trillium†Machine Learning Processor Architecture†were introduced from different perspectives. It is worthy of our careful analysis.
ARM disclosed that its ML Processor was on the eve of the Spring Festival this year. At that time, there was not much information released. I also made a simple analysis (AI chip was launched).
This time, ARM disclosed more information. Let's take a look. The first is the key Feature and some important information. The 2018 Conference will release.
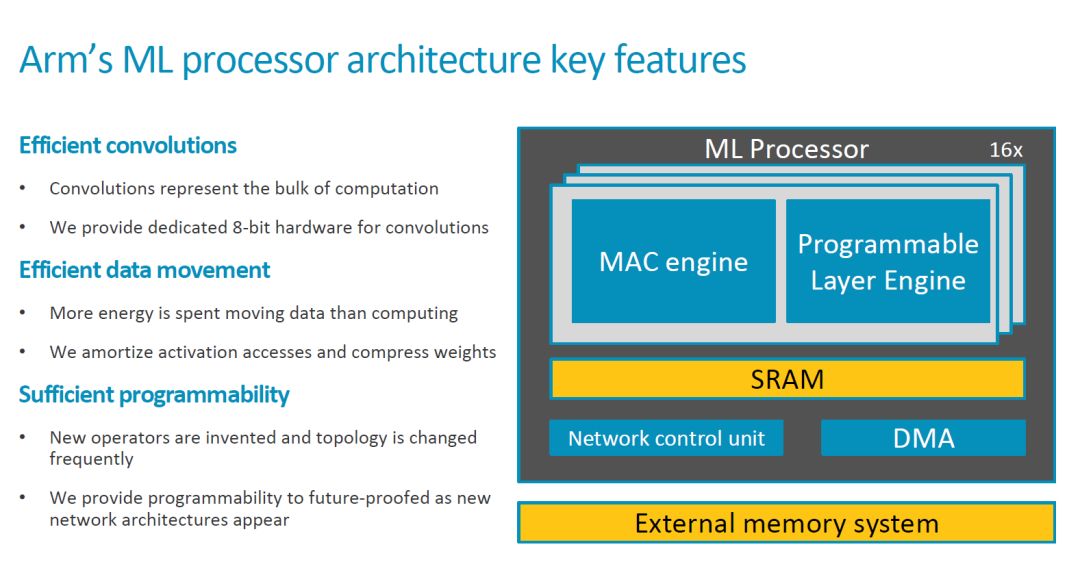
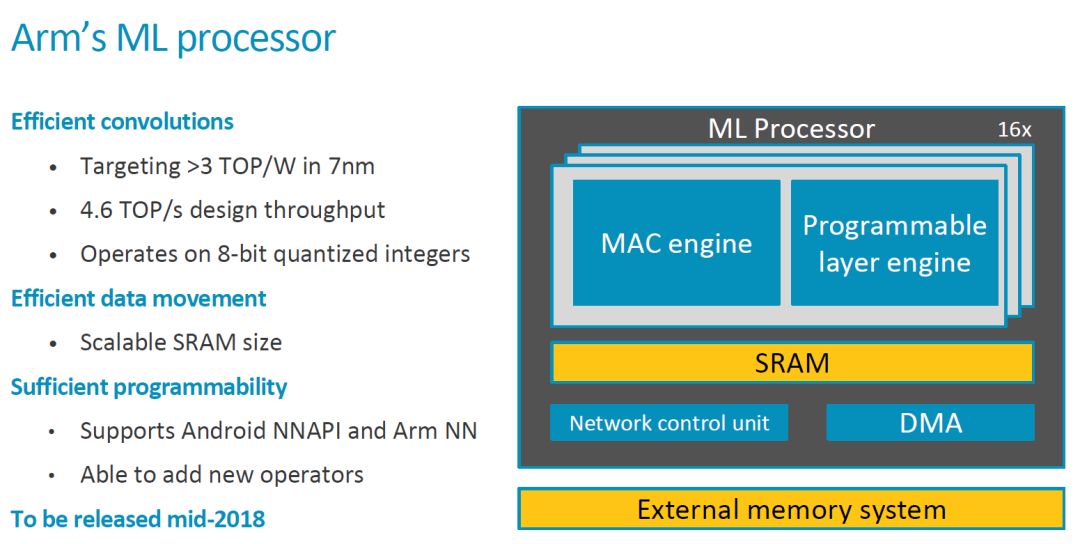
•••
Top-level architecture
Compared with the basic block diagram initially published, we have seen a more detailed block diagram and connection relationship this time, as shown in the figure below.
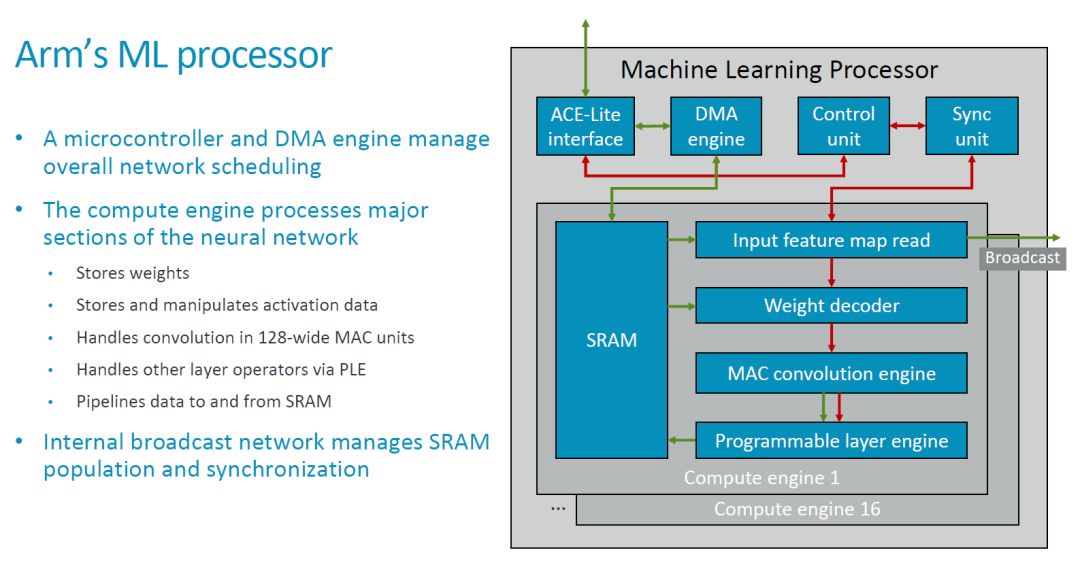
The top layer of MLP is a typical hardware accelerator from the outside. It has local SRAM, interacts with external data and main control information (instructions) through an ACE-Lite interface. There should also be some control signals that are estimated to be omitted here (see Nvidia's NVDLA).
In the above figure, the green arrow should indicate the data flow, and the red color indicates the control flow. The CE in MLP shares a set of DMA, Control Unit and Sync Unit. The basic processing flow is as follows: 1. Configure the Control Unit and DMA Engine; 2. The DMA Engine reads data from the outside (such as DDR). SRAM; 3. Input Feature Map Read module and Weight Read module read the feature map and weight to be calculated, processing (such as the decompression of Weight), and sent to the MAC Convolution Engine (hereinafter referred to as MCE); 4. MCE Perform operations such as convolution, and transfer the result to the Programmable Layer Engine (hereafter referred to as PLE); 5. PLE performs other processing and writes the result back to the local SRAM; 6. The DMA Engine transfers the result to an external storage space (such as DDR) ).
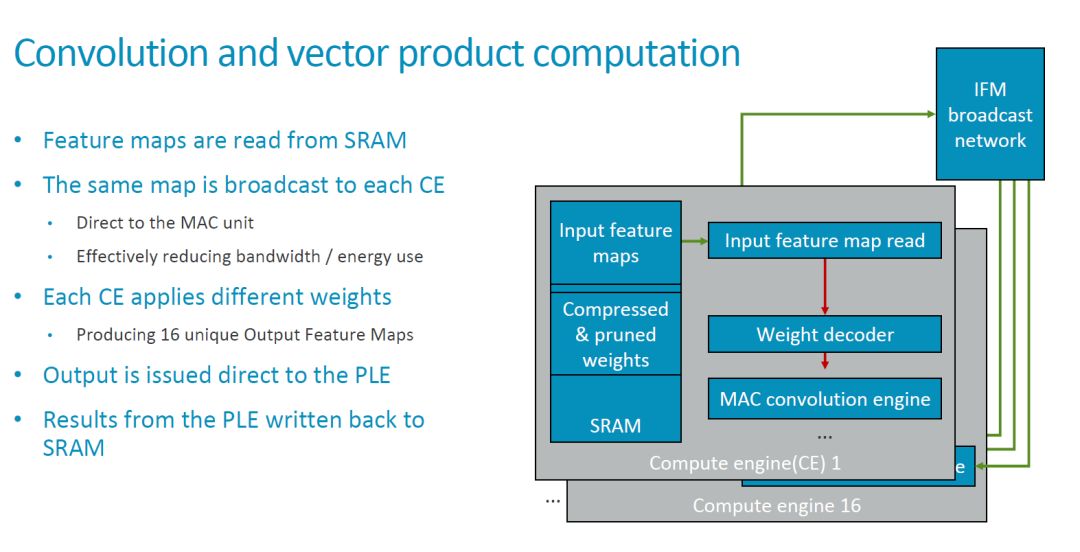
The broadcast interface marked at the top layer implements the function of broadcasting feature map data between multiple Compute Engines (hereinafter abbreviated as CE). Therefore, the basic convolutional operation mode is that the same feature map is broadcast to multiple CEs, and different CEs use different weights to operate on these feature maps.
From the current configuration point of view, MLP includes 16 compute engines, each with 128 MACs, that is, a total of 16x128=2048 MACs, each cycle can perform 4096 operations. If you want to achieve ARM's total processing power of 4.6 TOPS, you need a clock cycle of about 1.12 GHz. Since this indicator is for a 7nm process, the problem is not significant.
•••
MCE achieves efficient convolution
In the MLP architecture, MCE and PLE are the most important functional modules. The MCE provides the major computing power (processing 90% of the calculations) and should be the largest area and power consumption in the MLP. Therefore, a major goal of MCE design optimization is to achieve efficient convolution operations. Specifically, the design of MLP mainly considers the following methods, most of which we have discussed before.
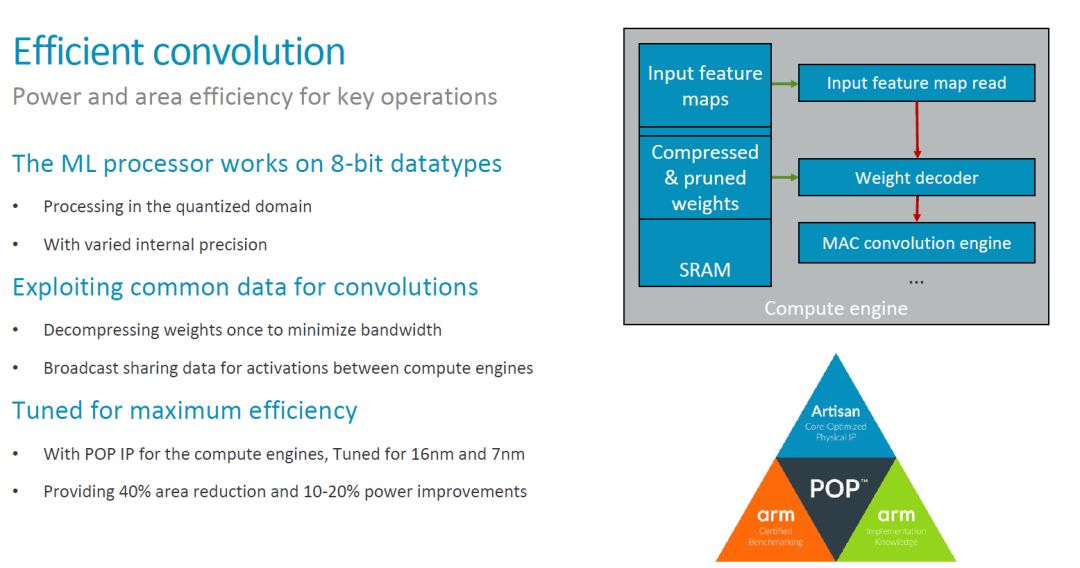
One of the more interesting points is the "varied internal precision" mentioned above. It is not yet clear what its specific meaning is. However, the application should see a fixed 8-bit data type. As for support for low precision Inference, the information provided in [1] is, "The team is tracking research on data types down to 1-bit precision, including a novel 8-bit proposal from Microsoft. So far, the alternatives lack support In tools to make them commercial viable, said Laudick." So in the first version of the MLP, you should not see low-precision or Bit-serial MAC anymore (see Bit-serial Processing for ISSCC 2018 in the beginning of the AI ​​chip.) Introduction.)
In addition, the data compression and optimization of the process are also the main means to improve the overall efficiency. In particular, optimization of the process, combined with ARM's technology library, should have better results. This is where ARM has an advantage.
•••
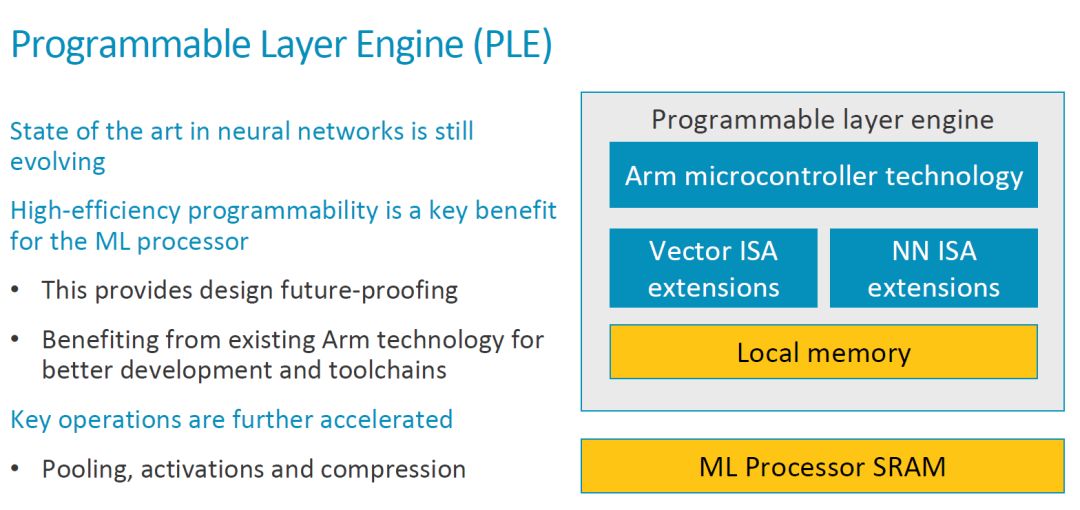
PLE achieves efficient programmability
As shown in the figure below, the structure of the PLE basically extends the instruction of Vector processing and NN processing on an ARM MCU. When discussing programmability, the starting point is mainly that the NN algorithm and architecture are still evolving.
We have already analyzed the basic workflow of the entire MLP. The MCE transfers the result to the PLE after completing the operation. From this, it can be seen that the MCE should send the result to the Vector Register File (VRF) and then generate an interrupt to inform the CPU. After that, the CPU starts Vector Engine to process the data. Specific as shown below.
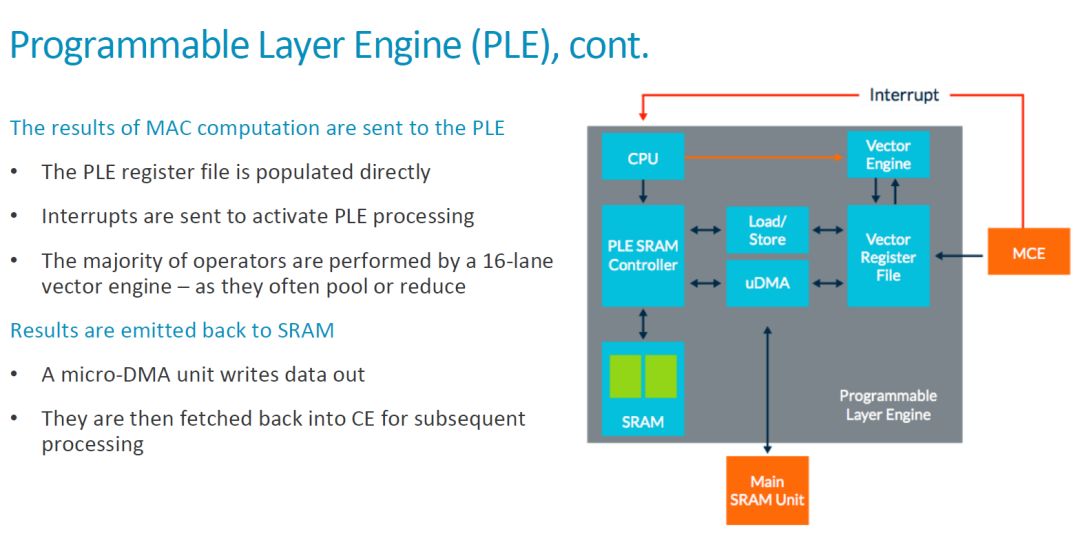
For a classmate who is a dedicated processor, the architecture of this scalar CPU+vector engine is not new. Here, load/store units and uDMA are used to transfer data between the local SRAM, the Maing SRAM Unit (SRAM in CE) other than VRF and PLE, and the data flow is also flexible. In a comprehensive view, in the MLP, there is one PLE and MCE in each CE. That is, each MCE (128 MACs) corresponds to a programmable architecture. Therefore, ARM MLP's programmability and flexibility are much higher than that of Google TPU1 and Nvidia's NVDLA. Of course, flexibility also means more extra overhead, as noted in [1], "The programmable layer engine (PLE) on each slice of the core offers "just enough programmability to perform [neural-net] manipulations"" . High-efficient Programmability is one of the major selling points of MLP, and ARM’s “Just enough†is really the most suitable choice. It needs to be further observed.
•••
Other Information
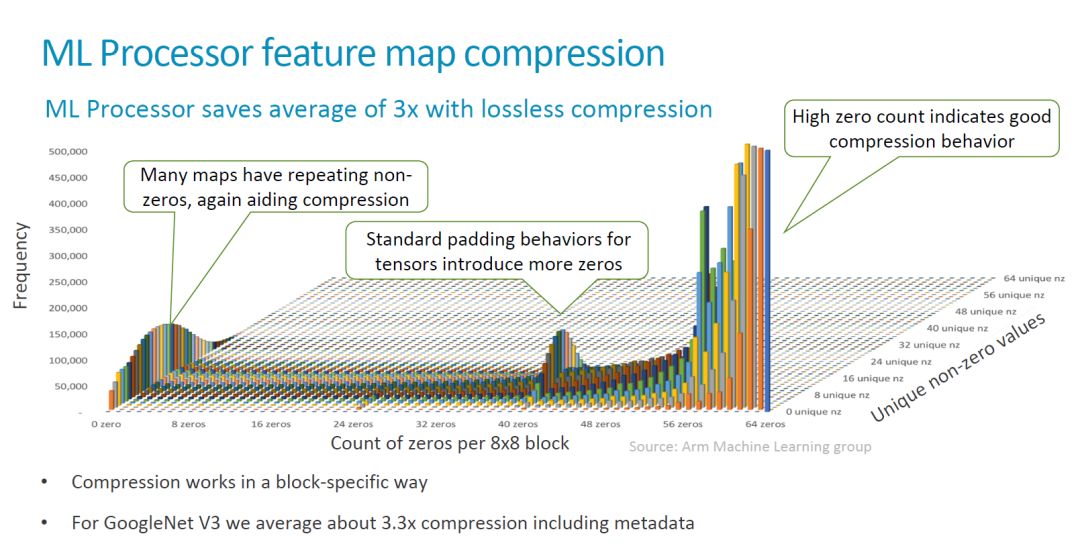
In this release of information, ARM also emphasized their considerations in data compression, including hardware support for lossless compression. This part of the content of my previous article also has more discussion, will not repeat them, paste a few more interesting map, we see.

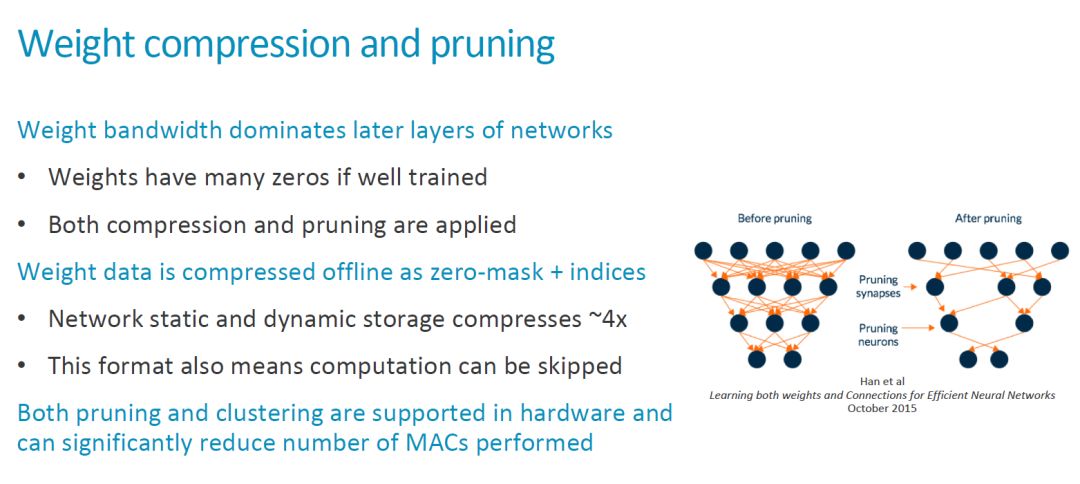
As an IP core, configurability is an important feature. At present, it is not known which hardware parameters of MLP can support flexible configuration. The number of Compute Engines, the number of MACs, and the size of the SRAM, these larger parameters should probably support configuration. Other more detailed content depends on the final release. In addition, the configuration of these parameters is closely related to the related software tools. More configurable parameters also mean that the software tools need corresponding support and it is more difficult. [2]For this argument: "In terms of scalability the MLP is meant to come with configurable compute engine setups from 1 CE up to 16 CEs and a scalable SRAM buffer up to 1MB. The current active designs are the 16CE and 1MB. Configurations and smaller scaled down variants will happen later on in the product lifecycle."
•••
Competitive situation
In addition to relatively satisfactory performance indicators, ARM has not announced the specific area of ​​MLP, power consumption and other parameters, as well as the date of the specific release (currently, "production release of the RTL is on track for mid-year").
In this already "crowded" market, ARM is clearly slow. [1] Mentioned at the beginning, "Analysts generally praised the architecture as a flexible but late response to a market that is already crowded with dozens of rivals." and listed some examples of competitors.
In fact, from the perspective of ARM's key position in the processor IP market and the entire ecological chain, the relationship is not much later. As [1] said, on the one hand, ARM is working in depth with some smart phone manufacturers. "In a sign of Arm's hunger to unseat its rivals in AI, the company has "gone further than we normally would, letting [potential Smartphone customers] look under the hood"â€.
Another important advantage of ARM is that ARM still has some preparations for software tools before launching MLP, including armnn and open source computing libraries, etc., as shown below.
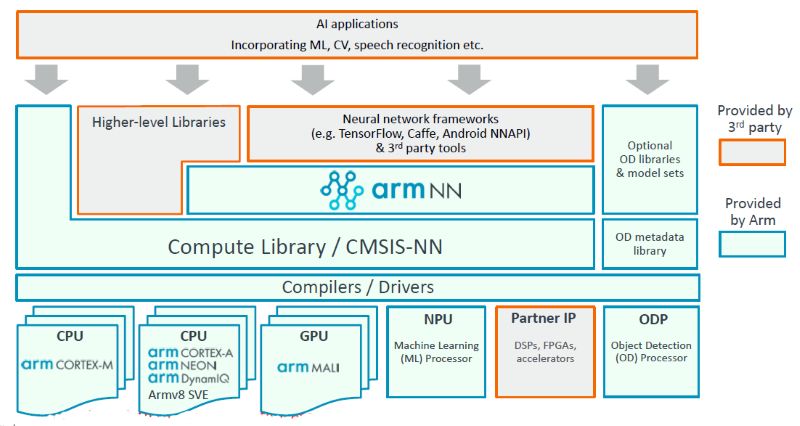
The extensive use of these tools can help ARM gain experience and optimize hardware and software tools. As quoted from ARM in [1], "Winning the hearts and minds of software developers is increasingly key in getting design wins for hardware sockets...This is kind of the start of software 2.0. For a processor company, that is Cool. But it will be a slow shift, there's a lot of things to be worked out, and the software and hardware will move in steps."
We also see that a large number of embedded AI applications are still running on various ARM hardware. Many companies have invested a great deal in the optimization of related algorithms and implementations, and have also achieved good results. Of course, this brings another interesting question, that is, after the introduction of MLP in the future, where does the ML task go? How to match the different characteristics of the processor? This article just mentioned this issue, "Arm will release more data on the core's performance when it is launched, probably in mid-June. But don't expect detailed guidance onwhen to run what AI jobs on its CPU, GPU, or New machine-learning cores, a complex issue that the company, so far, is leaving to its SoC and OEM customers." It seems that this "hard problem" is still lost to users in the short term.
Another noteworthy detail is mentioned in [1], "Theoretically, the design scales from 20 GOPS to 150 TOPS, but the demand for inference in the Internet of Things will pull it first to the low end. Arm is still debating. Whether it wants to design a core for the very different workloads of the data center that includes training. “We are looking at [a data center core], but it's a jump from here,†and its still early days for thoughts on a design Specific for self-driving cars, said Laudick." It can be seen from this that at least MLP is still more scalable in processing power and should cover most of the inference applications from Edge to Cloud. If it is the highest 150TOPS, the size of the MAC should be similar to Google's first generation of Inference-specific TPU, but compared to Google's systolic array architecture, MLP has more complex control channels, and the flexibility is still much higher. Do not know the future, this will not help ARM open data center inference market.
reference:
1. "Arm Gives Glimpse of AI Core", https://?doc_id=1333307
2. "ARM Details "Project Trullium" Machine Learning Processor Architecture", https://
Outdoor Cpe,Router 4G Outdoor,4G Router Bridge Cpe,300Mbps Wifi Ap Outdoor 4G Lte Cpe
Shenzhen MovingComm Technology Co., Ltd. , https://www.movingcommiot.com