The Voronoi diagram is a spatial segmentation algorithm. It is for n discrete points in space, which divides the plane into n regions, each region including a point, which is the set of points closest to the point. Because the Voronoi diagram has many properties such as the nearest neighbor, adjacency and perfect theoretical system, it is widely used in geography, meteorology, crystallography, aerospace, robotics and other fields.
Voronoi diagrams are mainly generated by vector methods and raster methods. In the vector method, the typical methods are the incremental method, the divide and conquer method, and the indirect method. Divide and conquer is a recursive method. The algorithm is simple, but it is difficult to implement dynamic update in the application process. The indirect rule is to construct a Voronoi diagram based on its dual graph Delaunay triangulation, so its performance is determined by the construction algorithm of the Delaunay triangulation used. The incremental method dynamically constructs a Voronoi diagram by continuously adding points to the generated Voronoi diagram. Compared with the first two methods, the incremental method is simple in construction and easy to implement dynamization, so it is widely used. The advantage of the vector method is that the Voronoi diagram is highly accurate, but there are storage complexities, growth elements can only be points and lines, and it is difficult to expand into three-dimensional and high-dimensional space. Therefore, this paper focuses on the raster generation method of Voronoi diagram. Firstly, the advantages and disadvantages of the common raster method for generating Voronoi diagram are compared. Then, based on the emergence of CUDA, a GPU-based Voronoi diagram parallel grid generation algorithm is proposed.
1 Introduction to the grid methodThe raster method generates a Voronoi diagram, which is mainly to convert a binary image into a raster image, and then determine the assignment of each blank raster. There are two main methods, one is centered on the blank grid, and the distance from each blank grid to the growth target is calculated to determine its attribution. Common methods include algebraic distance transformation method, blank grid determination method, etc. A class of growth targets is centered on the distance radius of the growth target, and the blank grid is filled until the entire image is filled, mainly including the circular expansion method and the mathematical morphology distance transformation method. The algebraic distance transformation method scans the distance image up (up to down, left to right) and down scan (from bottom to top, right to left) to calculate the nearest growth target of each blank grid. With this growth target as its attribution. The definition of the grid distance in this method directly affects the attribution of the blank grid and the generation accuracy of the Voronoi diagram. The commonly used grid distance defines the block distance, the octagonal distance, the board distance and so on. The distance-generated raster generation method has low precision and long time, and the time required is proportional to the number of grids. When the grid is n×n, the time complexity is O(n×n). The circle detection method takes the growth target as the center of the circle, and takes a certain step size as the initial radius, and all the growth targets simultaneously cover the blank grid in the circle formed by the same. By continuously expanding the radius of the growth target, more and more blank grids will be covered by the individual circles until the entire image is finally covered. The mathematical morphology distance transformation method is similar to the circle detection method. Its idea comes from the expansion operation in mathematical morphology. The expansion operation plays an important role in expanding the image. By continuously expanding the growth target, it finally expands to all the blank grids. . These two methods have a common shortcoming. After each expansion, it is necessary to judge whether the entire raster image has been expanded, and this requires traversing the raster image, which is very time consuming.
2 Grid generation method under GPU2.1 CUDA programming model and GPU
CUDA is a parallel programming model and a software programming environment. It uses C language as a programming language and provides a large number of high-performance computing instruction development capabilities, enabling developers to build a more efficient GPU's powerful computing power. Intensive data computing solution.
CUDA uses the CPU as the host side, the GPU as the device side, and one host side can have multiple devices. The CPU and GPU work together. The CPU is mainly responsible for the serial computing part of the program. The GPU is mainly responsible for the parallel computing part of the program. The code running on the GPU is called a kernel function, which can be executed in parallel by multiple threads built into the GPU. A complete task handler consists of a CPU-side serial processing code and a GPU-side parallel kernel function. When the CPU executes the GPU code, it first copies the relevant data to the GPU, and then calls the GPU's kernel function. Multiple threads in the GPU execute the kernel function in parallel. When the calculation is completed, the GPU returns the calculated result. To the CPU, the program continues to execute. By using GPU parallel processing to transfer time-consuming and parallel-processable calculations in the program to the GPU, the entire program can be run faster. CUDA is a three-layer organization structure of thread grid (Grid), thread block (Block) and thread (Thread). Each grid is composed of multiple thread blocks, and one thread block is composed of multiple threads, such as Figure 1 shows. In the GPU, threads are the smallest unit that runs in parallel. It can be seen that when there are a large number of threads, the degree of parallelism of the program will be very high. Currently, a grid on a GPU contains up to 65535×65535 thread blocks, and a thread block usually has 512 or 1024 threads, so theoretically, 65535×65535×512 grids can be simultaneously calculated.
2.2 Parallel Voronoi graph raster generation algorithm
In the traditional grid generation algorithm, whether it is to determine the attribution of the blank grid as the center, or to cover the blank grid by increasing the growth target radius centered on the growth target, they calculate each blank. When the grid distance is used, it can only be processed one by one by traversing the grid. An important feature of the raster processing process is that the calculation of each raster does not depend on the calculation results of other rasters. That is to say, the calculation of each grid is independent of each other, and due to the seriality of the CPU, each grid can only be processed sequentially, which reduces the processing speed.
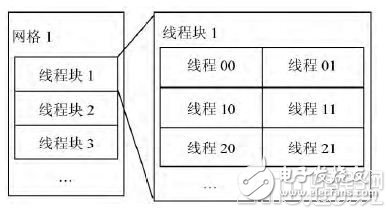
Figure 1 GPU organization
Since multiple threads under the GPU are implemented by hardware, the processing of each thread is parallel. Therefore, the calculation of the grid distance is distributed to each thread on the GPU side, which inevitably increases the generation speed. In order to process rasterized images in parallel, the following idea can be used to map each grid point to a thread that calculates the distance of the grid to all growth targets, taking the growth target of the minimum distance as its attribution. That is, a thread is used to determine the method of a blank grid attribution.
After determining the method, the GPU-side kernel function needs to be designed. Since the kernel function is the execution unit of parallel processing, the design method directly determines the program running efficiency of the GPU. So how to design a good kernel function is the key to improving parallel speed. In this paper, the kernel function is designed as follows. It is assumed that K parallel processing threads are allocated, the grid size is M×N, and A[i] is the grid number processed by the i-th thread. When K
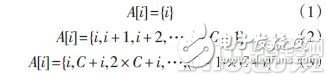
Since the memory on the graphics card is Dynamic Random Access (DRAM), the most efficient access method is to access in a continuous manner. When using the first method, it seems to be a continuous access method, which actually happens to be non-contiguous. When the i-th thread processes the i-th raster, the processing takes a certain time, and the GPU automatically The memory data required by the next thread i+1 is taken out to its use. At this time, the memory data of the next thread is at i+C, and the memory becomes intermittent access. When using the second method for processing, it happens to be a continuous access method. Since the i-th thread is processing the i-th raster data, the GPU prepares data for the i+1th thread. The data at the time is exactly the i+1th memory. Satisfy the continuous access characteristics of the memory. So this article uses the second way, the pseudo code of the kernel function design is as follows:

The specific steps are as follows: (This assumes that the size of the grid is M × N):
Step1: According to the scale of the raster image, determine the allocation mode and the number of allocations of the GPU-side thread block and the thread, and initialize the parameters of the GPU.
Step2: The program calls the GPU-side kernel function and passes the raster image data to be processed to the GPU. The data is mainly the grid distance of the image, generally a two-dimensional array, 0 means a blank grid, and other growth targets can be defined by different numbers such as 1, 2, etc.
Step3: The GPU allocates M×N threads to process the raster. When M×N is greater than the total number of all threads, M×N rasters can be processed into blocks, that is, divided into A rows×B columns×C blocks. , where A×B is less than the total number of threads. For a grid divided into C blocks, each thread only needs to process C rasters.
Step4: When the number of growth targets is small, each thread calculates the distance of its corresponding grid to all growth target points, and takes the growth target with the smallest distance. For the attribution of the blank raster corresponding to this thread, go to Step 6. When there are too many growth targets, go to Step 5.
Step5: When there are more growth targets, in order to reduce the time of traversing the growth target, by referring to Wang Xinsheng's algorithm, the distance from the grid point to each growth target is not calculated, and the neighborhood expansion is continued until the blank grid is reached. The method of target growth point determines the attribution of this grid.
Step 6 returns the generated data to the CPU, and the CPU completes the display and post-processing of the raster image.
3 Experiments and conclusionsIn the test parameters of IntelXeonCPUE5-2609, 2.4GHz, 2 processor 8 core, GPU parameters of TeslaC2075, 448CUDA core, and 5.25GB of memory, different methods were used to generate Voronoi diagrams at different grid scales. The number of growth targets in the experiment was defined as 100. Since different methods use the same distance definition, the Voronoi diagram generation results of the various methods are the same, that is, the generation precision between them is the same, so here we focus on the generation time of different methods. Table 1 lists the time when different methods are used to generate Voronoi diagrams. Figure 2 shows the line diagrams of Table 1. As can be seen from Figure 2, when the number of grids is small, the use of GPU parallel technology does not improve the generation speed. However, when the number of grid points increases, the point-by-point method and the distance transform method increase significantly, but the GPU parallel algorithm takes almost no change.
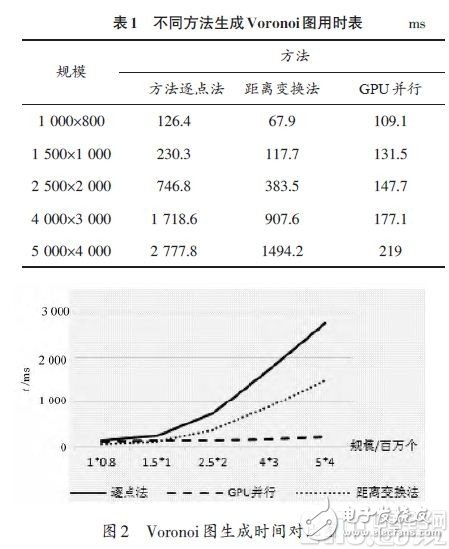
It can be seen from the experimental results that the GPU can be used to accelerate the generation of the Voronoi diagram in parallel, which can improve the generation speed. The time required to generate the Voronoi diagram is related only to the number of growth targets, and has nothing to do with the grid scale. When the number of growth targets is n, the time complexity is approximately O(n), which is a linear generation time. Compared with the previous several CPU serial algorithms, especially when the grid size is too large, the generation speed of the Voronoi diagram can be improved.
ZGAR FILTER TIP
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

Vape Filter Tip,Disposable Pod Vape,Disposable Vape Pen,Disposable E-Cigarette,Electronic Cigarette,OEM vape pen,OEM electronic cigarette.
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.szdisposable-vape.com