Joint compilation: Blake, Gao Fei
Editor's Note: Professor Michael I. Jordan is a Distinguished Professor of the Department of Electronic Engineering, Computer Science, and the Department of Statistics at the University of California, Berkeley. He earned a master's degree in mathematics from Arizona State University and a Ph.D. in cognitive science from the University of California, San Diego in 1985. From 1988 to 1998, Michael I. Jordan was professor at the Massachusetts Institute of Technology (MIT). His research interests include computational, statistical, cognitive, and biological sciences. He has focused on Bayesian nonparametrics in recent years . Analysis, probabilistic graph models, spectral methods, kernel machines and their applications in distributed computing systems, natural language processing, signal processing, and statistical genetics (almost covers most of the machine learning content).

Professor Michael I. Jordan is a member of the National Academy of Sciences, a fellow of the National Academy of Engineering, and a fellow of the American Academy of Arts and Sciences. He was appointed by the Institute of Mathematical Statistics as Neyman Lecturer and Medallion Lecturer. In 2016, he received the IJCAI Excellence in Research Award. In 2015, he won the David E. Rumelhart Award; in 2009, he won the ACM/AAAI Allen Newell Award. At the same time, he is a member of AAAI, ACM, ASA, CSS, IEEE, IMS, ISBA and SIAM.
Many of the students who have studied at Professor Michael I. Jordan have grown up in the field, including the great God of deep learning, Professor Yoshua Bengio of the University of Montreal, and the current Chief Scientist of Baidu American Researcher and Professor of Stanford University Andrew Ng. (Wu Enda), there are professors from Stanford University in the academic community, Percy Liang, and others. This article is the content of Michael I. Jordan 's lecture on computing thinking , reasoning thinking, and data science at UC Berkeley .


On Computational Thinking, Reasoning Thinking and "Data Science"
Michael I Jordan
University of California, Berkeley

Example: A job description (approximately 2016)
If you are a graduate from Berkeley, the need to go to Silicon Valley when you graduate.
Boss: "I need a big data system, using a personalized service to replace the original classic service."
"This system works well for anybody. I can accept a little mistake but not stupid mistakes that would make us paralyzed."
Michael I Jordan: This means to reduce your error rate to a particularly low level. If the correct rate is 99%, then another 1% of users encounter a number that is quite large.
"It should run as fast as the original classic service."
Michael I Jordan: Can't be slower than the original service, but also in the proper budget.
"When we collect more data it can only be faster, especially not slow down."
Michael I Jordan: When the amount of data increases, the error rate will also increase accordingly, not necessarily the more data the faster the speed.
"There will be many people in this area who are concerned about the issue of strict privacy. These people contain many different customers."

Conceptual challenges
Data science requires a complete fusion of computational thinking and reasoning thinking (inferior thinking has been around for 300 years and has begun to embrace various ideas and can be integrated with each other).
What does computing thinking mean?
Abstraction, Modularity, Extensibility, Robustness, etc.
What does inference thinking mean?
Consider real-world phenomena behind the data
Taking into account the sampling pattern that produces the data
The development program will push backwards from the data to the underlying phenomenon

These challenges are daunting
The core theories in computational science and statistics are developed separately. There is an oil and water problem (incompatible factors).
There is no place for runtime and other computing resources in the core statistical theory
There is no statistical risk location in core computing theory

Warning: A lot of math knowledge ahead

Part One - Reasoning and Privacy

Privacy and data analysis
People are generally reluctant to use their personal data under uncontrolled circumstances, and at the same time worry about how much their privacy will be lost.
"Privacy Loss" can be quantified
We want to trade privacy loss with the value we get from "data analysis"
The problem then becomes to quantify these values ​​and put them together with the loss of privacy.
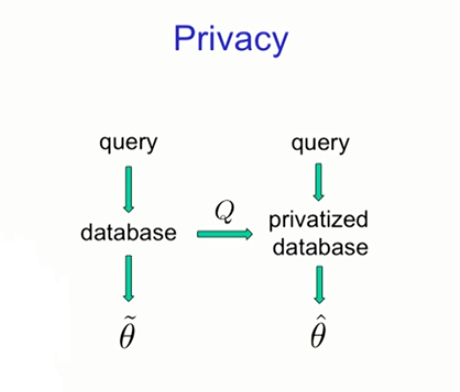
privacy
Doubt - database - private database
Computational thinking, but not reasoning. (For example, data shows people's age, height, weight, and blood pressure. Should they be treated with drugs? How long can they live?)
Reasoning thinking
Combine the two
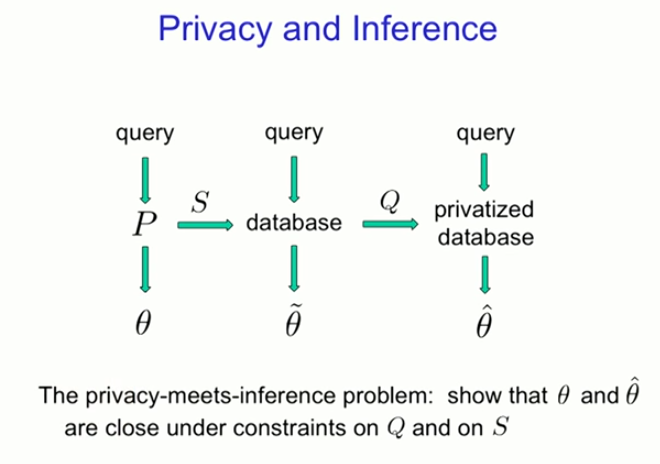
Privacy problems with reasoning

Private Data Analysis Maximal Minimalism
Let n denote the amount of data points, d denote the dimension of the parameter space, and a denote different privacy parameters
Rationale : If we replace n with an effective sample size, the maximum risk of privacy awareness is the same as the classical minimum risk

Introduction: Privacy Mean Estimate
Example: Estimated Cause of Patient Going to the Hospital
Drug abuse patients admitted to hospital
Estimates of substances that cause different prevalence

Introduction: Mean estimation

Optimization mechanism?
Non-privacy watch: People sometimes do not want to share some private data. In this regard, what methods should we use to analyze private data?
Point of View 1 : Increase heavy tail noise, using independent noise (for example, Laplace mechanism) as an example. Through this approach, you can get first-hand data.
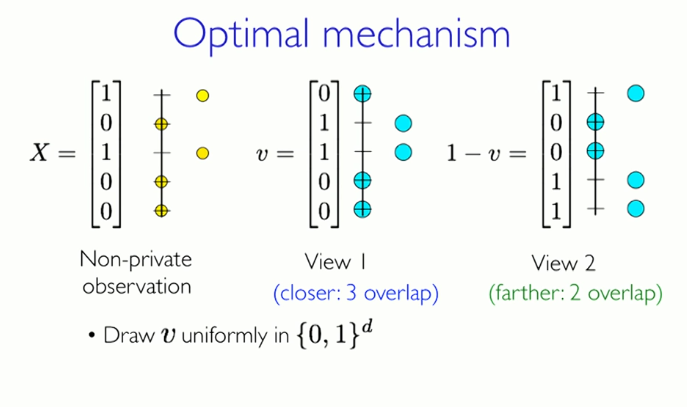
Optimization mechanism
Unified extraction of random vectors v from the set {0,1}
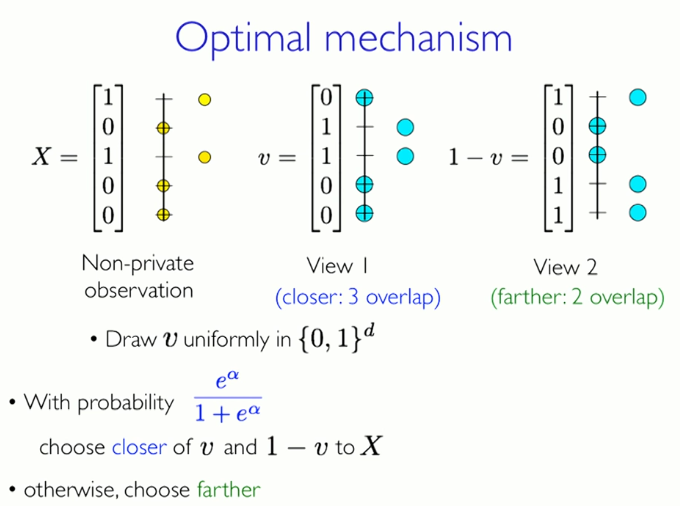
Unity extracts v from the set {0,1}
When the probability is , where α is the differential privacy parameter, select v and 1-v close to X
Otherwise, choose v and 1-v away from X
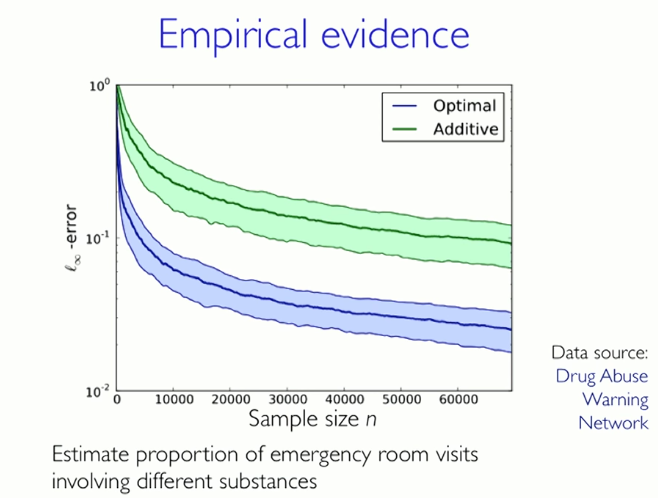
Empirical evidence
The extra data is a green curve and the blue curve corresponding to the logarithmic scale reflects this optimization mechanism. The trend of the green and blue curves shows a clear difference between the extra data and the optimized data.
Estimated proportion of incoming and outgoing emergency rooms due to different reasons
Source: Drug Abuse Warning Network

Part II: Reasoning and Compression
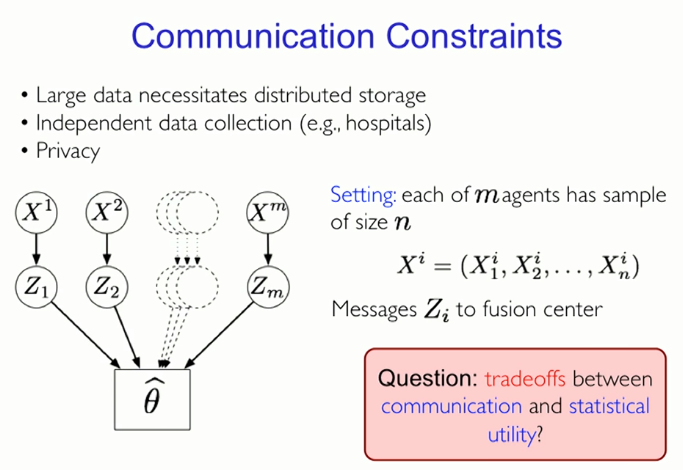
Communication constraints
The phenomenon of big data makes distributed data storage necessary (thus, Michael puts certain restrictions on the data in the data analysis system, that is, compression).
Independent data collection (for example, hospitals)
privacy
Setting: The number of samples for each m agent is n
Information transfer to the fusion center
Question: The trade-off between communication and statistical utility?

What is the big data phenomenon?
Validation model of science (eg, particle physics)
Reasoning issues: There are a large number of interfering variables
Explaining the science of patterns (eg, astronomy, genomics)
Reasoning issues: There are a lot of hypotheses
Measuring human activities, especially online activities, will produce large data sets that can be used for personalization or for market development
Reasoning issues: Many unknown sampling frames (with diversity), complex loss functions
There are computational problems
Most notably, computational problems and inference problems affect each other.
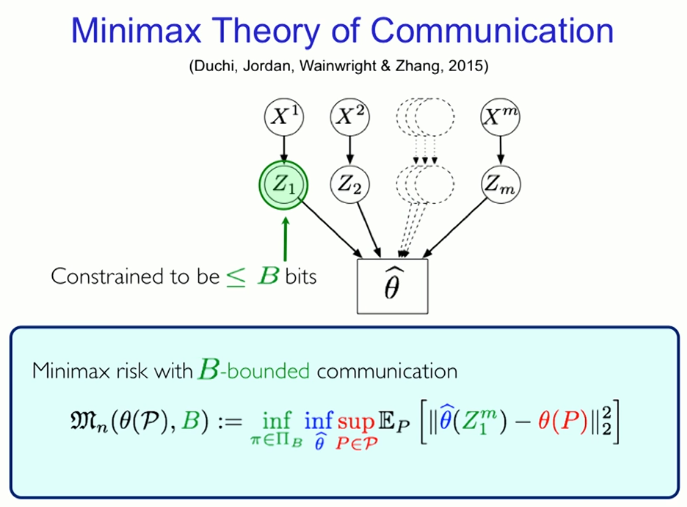
Maximal Minimal Communication Theory (Duchi, Jordan, Wainwright & Zhang, 2015)
Limit be to B-bit range
The maximum risk of communication within the scope of B constraints is shown above.

Introduction: Mean estimation
Calculate the average estimate in the normal local set θ
Principle: When the number of samples for each agent is n, the maximum and minimum rates are shown above.
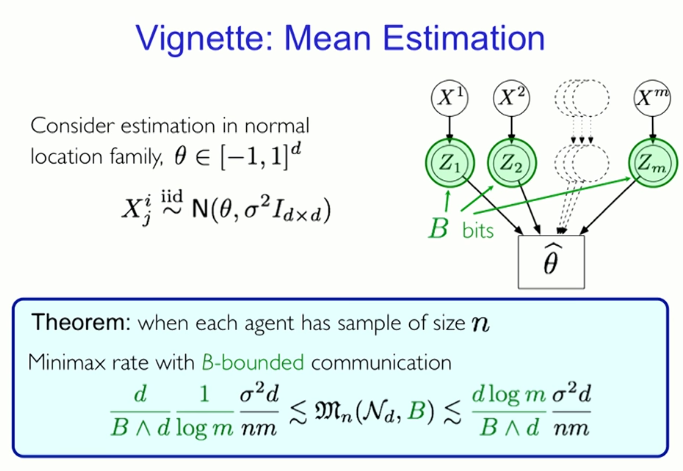
Principle: When the number of samples of each agent is n, the maximum and minimum rates of communication within the bounds of B are shown in the above figure.

discuss
There are many conceptual and mathematical challenges in dealing with data science issues
Facing these challenges requires a good relationship between " calculation thinking " and " reasoning thinking "
Establish links at the basic level in the areas of computing and inference
Related Reading
Geoffrey Hinton, the originator of deep learning, helps you get started
Depth Learning Great God Yoshua Bengio's classic forward-looking speech to help you get through to the deep learning
Deep Learning Yann Lecun Describes Convolutional Neural Network
Seconds understand! He Keming's deep residual network PPT is like this | ICML2016 tutorial
PS : This article was compiled by Lei Feng Network (search "Lei Feng Network" public number) and it was compiled without permission.
Via Michael I. Jordan